Maximum Likelihood Estimate
Contents
Maximum Likelihood Estimate#
Suppose we are given a problem where we can assume the parametric class of distribution (e.g. Normal Distribution) that generates a set of data, and we want to determine the most likely parameters of this distribution using the given data. Since this class of distribution has a finite number of parameters (e.g. mean \(\mu\) and standard deviation \(\sigma\), in case of normal distribution) that need to be figured out in order to identify the particular member of the class, we will use the given data to do so.
The obtained parameter estimates will be called Maximum Likelihood Estimates.
Let us consider a Random Variable \(X\) to be normally distributed with some mean \(\mu\) and standard deviation \(\sigma\). We need to estimate \(\mu\) and \(\sigma\) using our samples which accurately represent the actual \(X\) and not just the samples that we have drawn out.
Estimating Parameters#
Let’s have a look at the Probability Density Function (PDF) for the Normal Distribution and see what they mean.
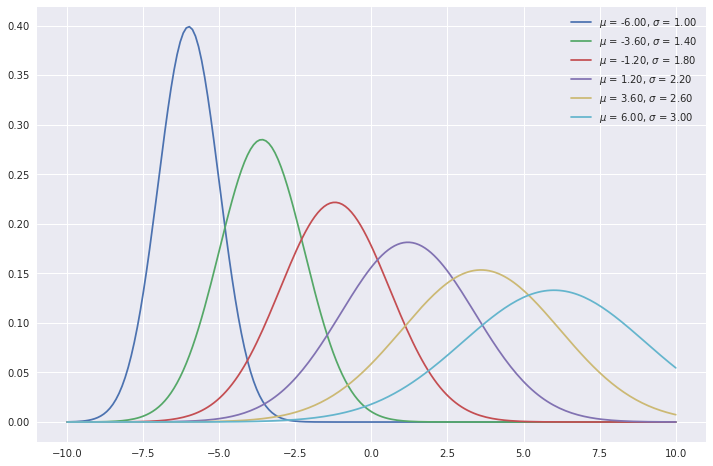
This equation is used to obtain the probability of our sample \(x\) being from our random variable \(X\), when the true parameters of the distribution are \(\mu\) and \(\sigma\). Normal distributions with different \(\mu\) and \(\sigma\) are shown below.
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
np.random.seed(10)
plt.style.use('seaborn')
plt.rcParams['figure.figsize'] = (12, 8)
def plot_normal(x_range, mu=0, sigma=1, **kwargs):
'''
https://emredjan.github.io/blog/2017/07/19/plotting-distributions/
'''
x = x_range
y = norm.pdf(x, mu, sigma)
plt.plot(x, y, **kwargs)
mus = np.linspace(-6, 6, 6)
sigmas = np.linspace(1, 3, 6)
assert len(mus) == len(sigmas)
x_range = np.linspace(-10, 10, 200)
for mu, sigma in zip(mus, sigmas):
plot_normal(x_range, mu, sigma, label=f'$\mu$ = {mu:.2f}, $\sigma$ = {sigma:.2f}')
plt.legend();
Let us consider that our sample = 5. Then what is the probability that it comes from a normal distribution with \(\mu = 4\) and \(\sigma = 1\)? To get this probability, we only need to plug in the values of \(x, \mu\) and \(\sigma\) in Equation (1). Scipy as a handy function norm.pdf() that we can use to obtain this easily.
from scipy.stats import norm
norm.pdf(5, 4, 1)
0.24197072451914337
What if our sample came from a different distribution with \(\mu = 3\) and \(\sigma = 2\)?
norm.pdf(5, 3, 2)
0.12098536225957168
As we can see, the PDF equation (1) shows us how likely our sample are from a distribution with certain parameters. Current results show that our sample is more likely to have come from the first distribution. But this with just a single sample. What if we had multiple samples and we wanted to estimate the parameters?
Let us assume we have multiple samples from \(X\) which we assume to have come from some normal distribution. Also, all the samples are mutually independent of one another. In this case, the we can get the total probability of observing all samples by multiplying the probabilities of observing each sample individually.
E.g., The probability that both \(7\) and \(1\) are drawn from a normal distribution with \(\mu = 4\) and \(\sigma=2\) is equal to:
norm.pdf(7, 4, 2) * norm.pdf(1, 4, 2)
0.004193701896768355
Likelihood of many samples#
In maximum likelihood estimation (MLE), we specify a distribution of unknown parameters and then use our data to obtain the actual parameter values. In essence, MLE’s aim is to find the set of parameters for the probability distribution that maximizes the likelihood of the data points. This can be formally expressed as:
However, it is difficult to optimize this product of probabilities because of long and messy calculations. Thus, we use log-likelihood which is the logarithm of the probability that the data point is observed. Formally Equation (2) can be re-written as,
This is because logarithmic function is a monotonically increasing function. Thus, taking the log of another function does not change the point where the original function peaks. There are two main advantages of using log-likelihood:
The exponential terms in the probability density function are more manageable and easily optimizable.
The product of all likelihoods become a sum of individual likelihoods which allows these individual components to be maximized rather than working with the product of \(n\) probability density functions.
Now, let us find the maximum likelihood estimates using the log likelihood function.
Here,
Thus, Equation (4) can be written as:
Values of parameters#
Now, we will use Equation (6) to find the values of \(\mu\) and \(\sigma\). For this purpose, we take the partial derivative of Equation (6) with respect to \(\mu\) and \(\sigma\).
Now, to find the maximum likelihood estimate for \(\mu\) and \(\sigma\), we need to solve for the derivative with respect to \(\mu = 0\) and \(\sigma = 0\), because the slope is 0 at the peak of the curve.
Thus, using Equation (7) and setting \(\frac{\partial}{\partial \mu}\ln\left[L(\mu, \sigma|x_1, x_2, ..., x_n) \right] = 0\), we get,
Thus, the maximum likelihood estimate for \(\mu\) is the mean of the samples.
Simialrly, using Equation (8) and setting \(\frac{\partial}{\partial \sigma}\ln\left[L(\mu, \sigma|x_1, x_2, ..., x_n) \right] = 0\), we get,
Thus, the maximum likelihood estimate for \(\sigma\) is the standard deviation of the samples.
An Example#
Let us now consider 5 samples with values 0, -5, 6, -9 and 8. We want to know the normal distribution from which all of these samples were most likely to be drawn. In other words, we would like to maximize the value of \(f(0, -5, 6, -9, 8)\) as given in Equation (1). Since we do not know the values of \(\mu\) and \(\sigma\) for the required distribution, we need to estimate them using Equations (9) and (10) respectively.
Using the formulae of \(\mu\) and \(\sigma\), we get,
samples = np.array([0, -5, 6, -9, 8])
mu = np.mean(samples)
sigma = np.std(samples)
print(f'mu = {mu:.2f} and sigma = {sigma:.2f}')
mu = 0.00 and sigma = 6.42
Let us plot the normal distribution with these values and also mark the given points.
x_range = np.linspace(-20, 20, 200)
plot_normal(x_range, mu, sigma)
plt.axhline(y=0)
plt.vlines(samples, ymin=0, ymax=norm.pdf(samples, mu, sigma), linestyle=':')
plt.plot(samples, [0]*samples.shape[0], 'o', zorder=10, clip_on=False);
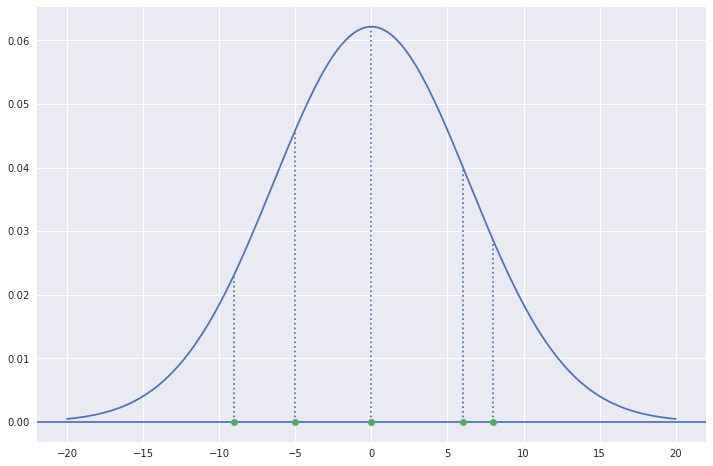
Thus, this is the most likely normal distribution from which the five sample points were drawn out.